Using Polars LazyFrames for Parallel Processing

If you’re looking for a more memory-efficient way to handle data transformations in Python, you may want to consider making the switch from the Pandas to Polars. For an in-depth explanation comparing the two libraries, take a look at my previous article Comparing Pandas and Polars for Data Transformations in Python.
In this article, we’ll take a look at how to utilize LazyFrames to supercharge our data transformations by leveraging the efficiencies already built into Polars (parallel processing, query optimization, etc.) for faster processing.
The example data below comes from a popular Pokémon dataset from Kaggle (The Complete Pokemon Dataset).

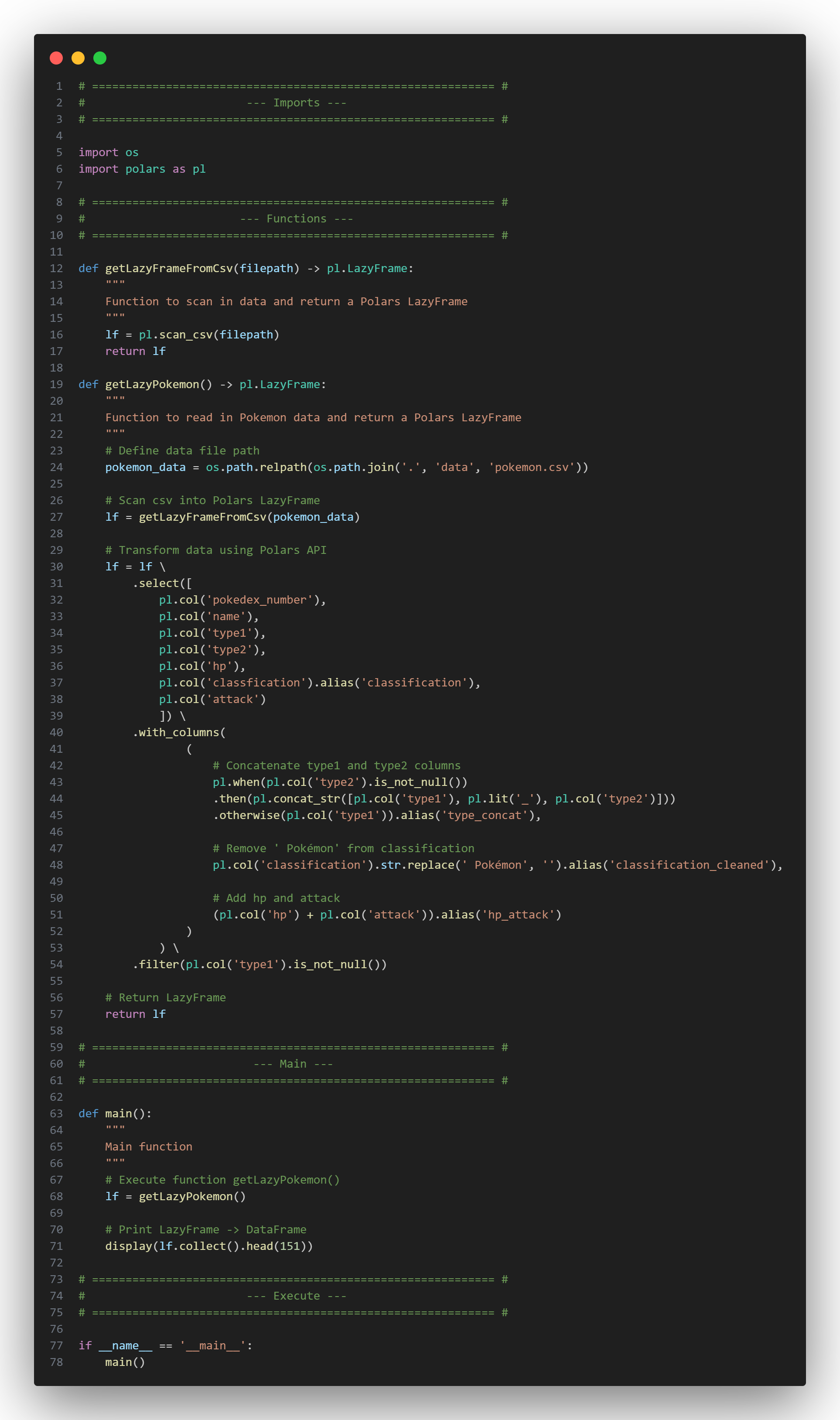
First, we need to import the "os" library to navigate to specific files and the "polars" library to create our ETL process.
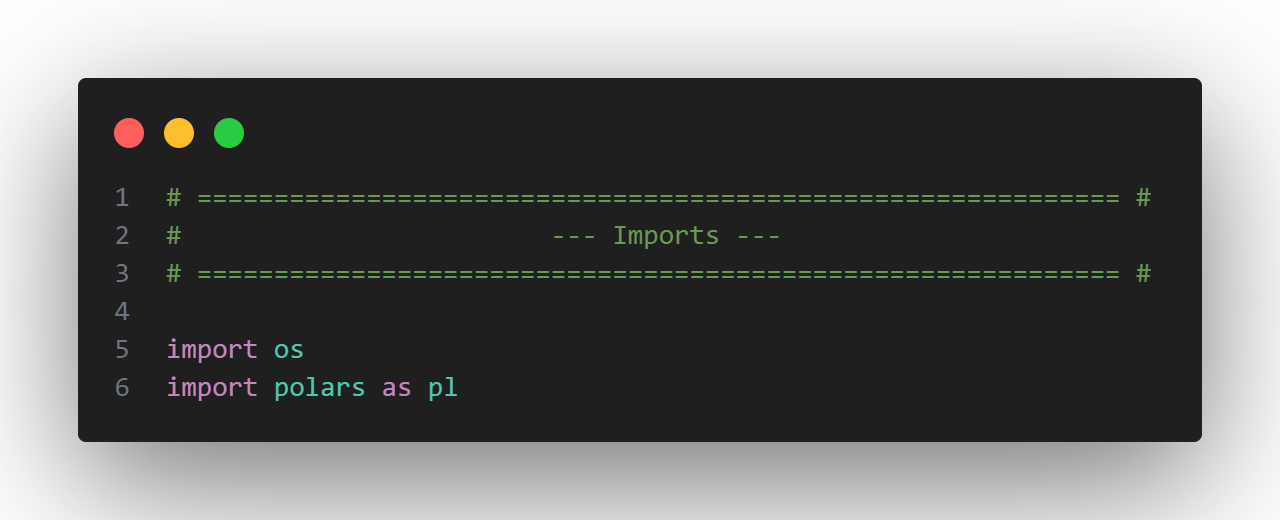
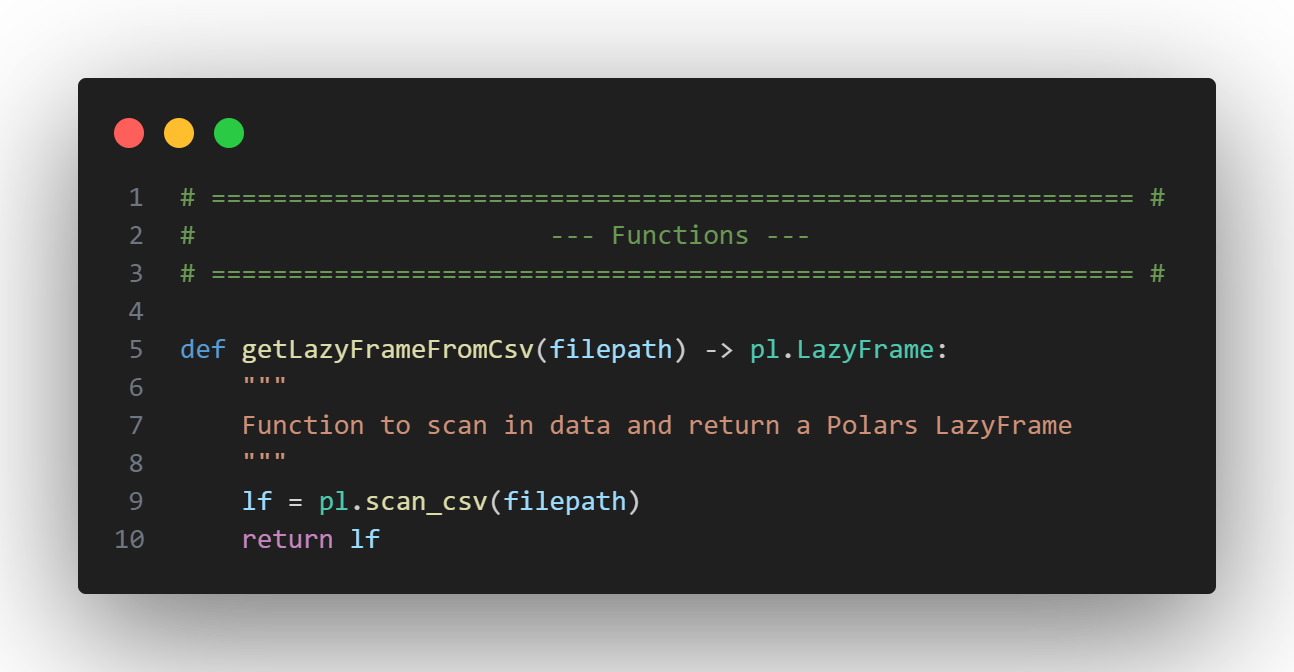
Next, we’ll create a function called getLazyFrameFromCsv() to take in a file path, scan the data, and return a Polars LazyFrame.
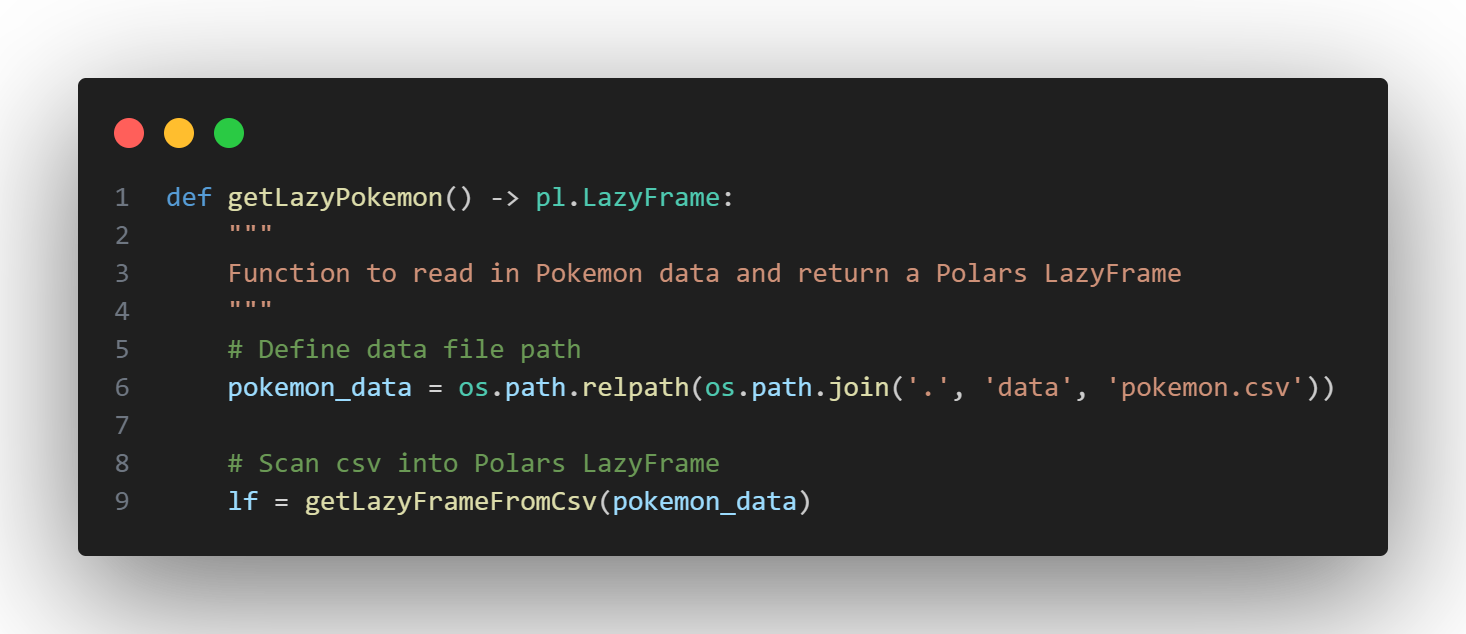
Using a new function called getLazyPokemon(), we will need to specify where the Pokémon data lives (using a relative file path) and call the getLazyFrameFromCsv() function to read in the data we'll be working with.
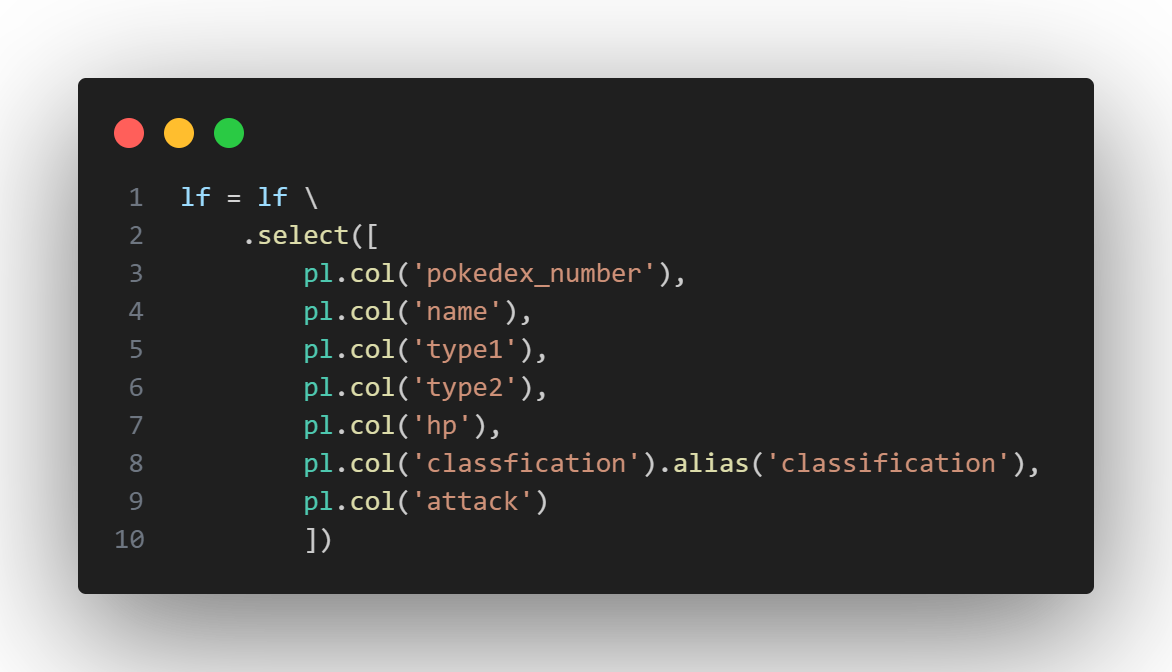
From this data, we’ll explore a few of the columns to get a sense of what we’re working with. Using the .select() method, we can specify the subset of columns we want – and correct a typo by using the .alias() method (on the 'classfication' column to make it appear as the correctly spelled 'classification').
We will also clean and transform the data to create a few new custom columns using the .with_columns() method and filter the results using the .filter() method before returning the updated LazyFrame.
Lastly, we’ll wrap all of that into a main() function to read and convert the LazyFrame to a DataFrame to display the data, then set it to execute main() when this script is run.
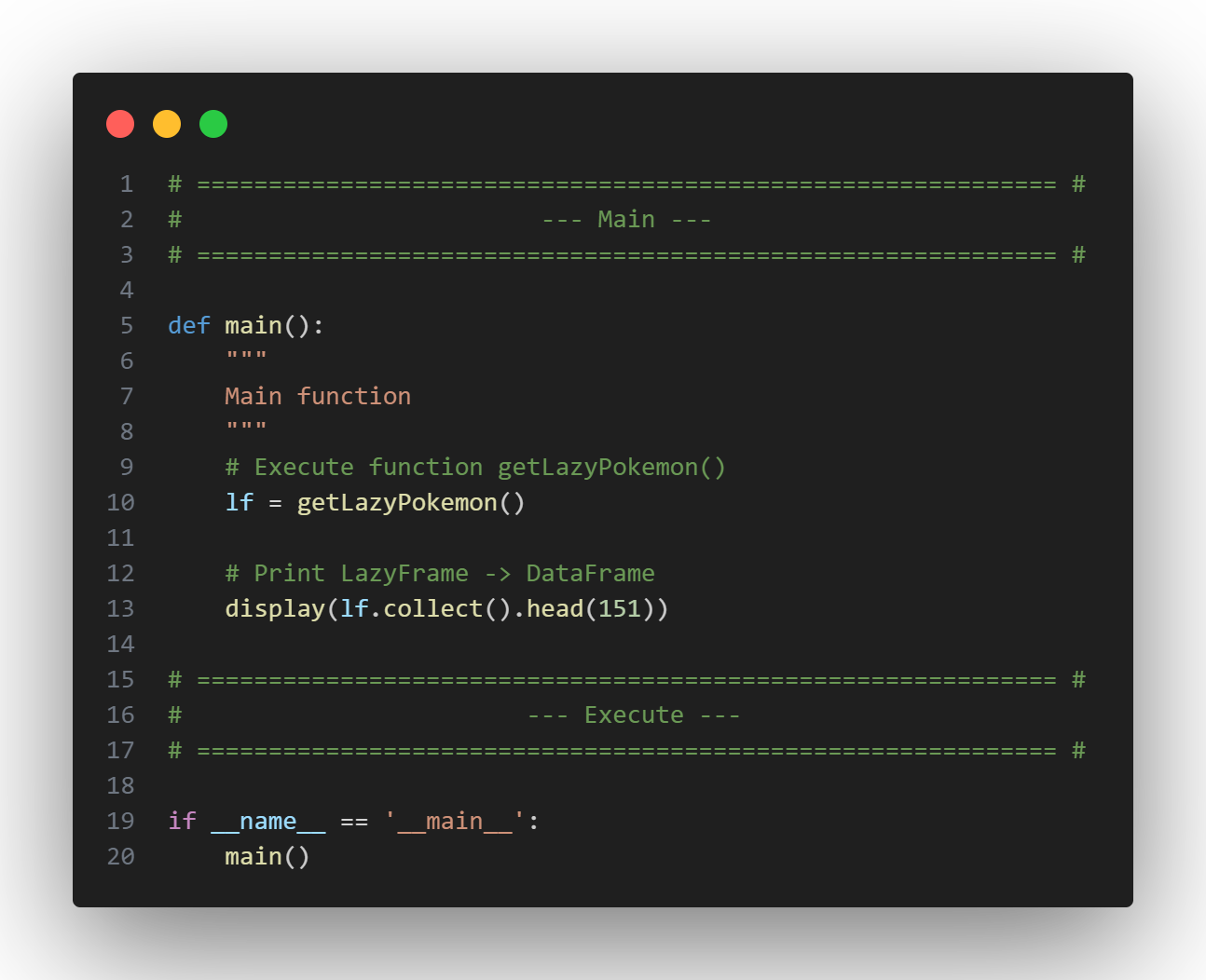
Here's the full script, followed by the output Polars DataFrame.
Script:
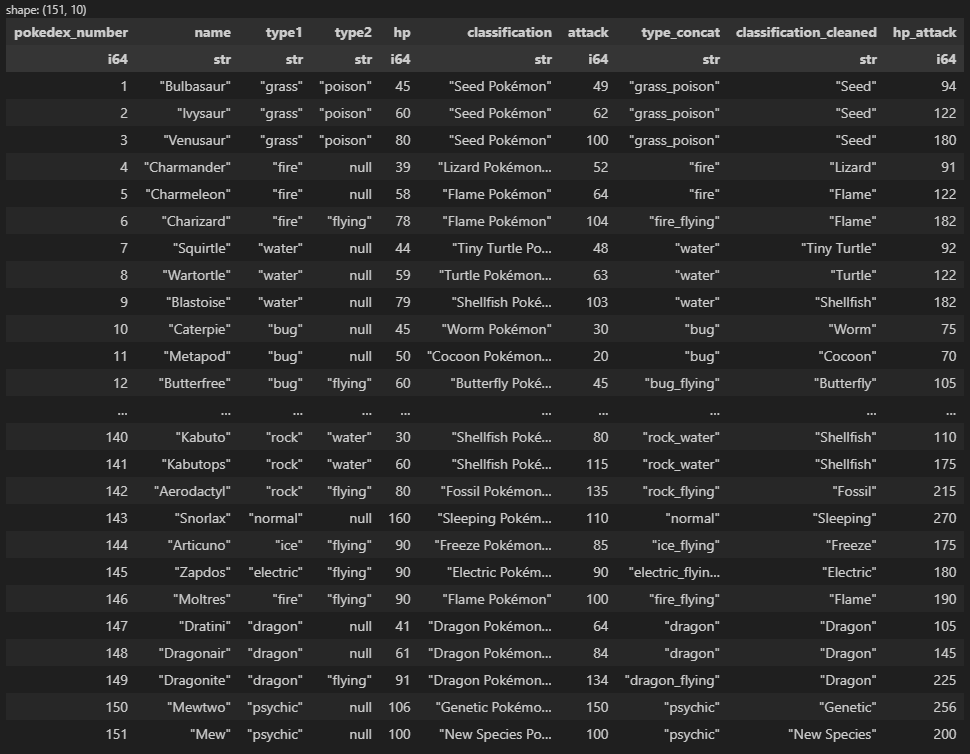
Output:
By utilizing the Polars Lazy API, we can update the query plan with transformation instructions as we go along. We can even pass LazyFrames from one function to another, just as we might normally do with a DataFrame.
As the LazyFrame continues to move through the script, it keeps updating the query plan, but the memory cost is much lower since it has not been loaded to a DataFrame object.
Once we call the .collect() method at the end of the script in the main() function, the query optimizer analyzes the entire query plan, finds the most efficient way to achieve the desired output, and converts the LazyFrame to a DataFrame to load the data.
With that, we've completed our ETL process for this Pokémon data!!

